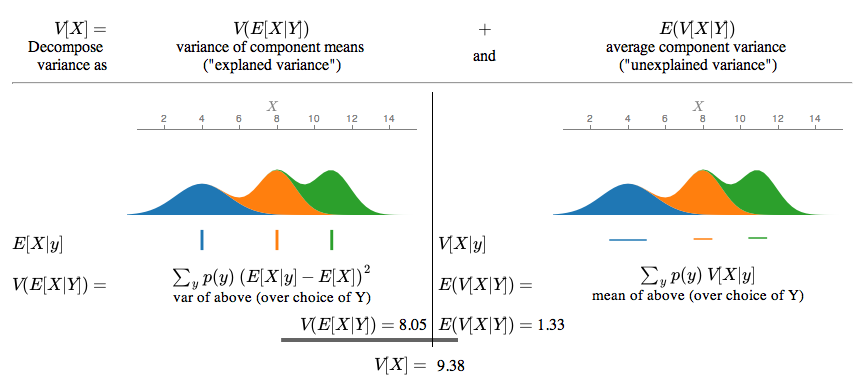
The law of total variance is a fundamental result in probability theory that expresses the variance of a random variable Y in terms of its conditional variances and conditional means given another random variable X. Informally, it states that the overall variability of Y can be split into an “unexplained” component (the average of within-group variances) and an “explained” component (the variance of group means).
Formally, if X and Y are random variables on the same probability space, and Y has finite variance, then:
This identity is also known as the variance decomposition formula, the conditional variance formula, the law of iterated variances, or colloquially as Eve’s law, in parallel to the “Adam’s law” naming for the law of total expectation.
In actuarial science (particularly in credibility theory), the two terms and are called the expected value of the process variance (EVPV) and the variance of the hypothetical means (VHM) respectively.
Explanation
Let Y be a random variable and X another random variable on the same probability space. The law of total variance can be understood by noting:
- measures how much Y varies around its conditional mean
- Taking the expectation of this conditional variance across all values of X gives , often termed the “unexplained” or within-group part.
- The variance of the conditional mean, , measures how much these conditional means differ (i.e. the “explained” or between-group part).
Adding these components yields the total variance , mirroring how analysis of variance partitions variation.
Examples
Example 1 (Exam Scores)
Suppose five students take an exam scored 0–100. Let Y = student’s score and X indicate whether the student is *international* or *domestic*:
- Mean and variance for international:
- Mean and variance for domestic:
Both groups share the same mean (50), so the explained variance is 0, and the total variance equals the average of the within-group variances (weighted by group size), i.e. 800.
Example 2 (Mixture of Two Gaussians)
Let X be a coin flip taking values Heads with probability h and Tails with probability 1−h. Given Heads, Y ~ Normal(); given Tails, Y ~ Normal(). Then
so
Example 3 (Dice and Coins)
Consider a two-stage experiment:
- Roll a fair die (values 1–6) to choose one of six biased coins.
- Flip that chosen coin; let Y=1 if Heads, 0 if Tails.
Then The overall variance of Y becomes
with uniform on
Proof
Discrete/Finite Proof
Let , , be observed pairs. Define Then
where Expanding the square and noting the cross term cancels in summation yields:
General Case
Using and the law of total expectation:
Subtract and regroup to arrive at
Applications
Analysis of Variance (ANOVA)
In a one-way analysis of variance, the total sum of squares (proportional to ) is split into a “between-group” sum of squares () plus a “within-group” sum of squares (). The F-test examines whether the explained component is sufficiently large to indicate X has a significant effect on Y.
Regression and R²
In linear regression and related models, if the fraction of variance explained is
In the simple linear case (one predictor), also equals the square of the Pearson correlation coefficient between X and Y.
Machine Learning and Bayesian Inference
In many Bayesian and ensemble methods, one decomposes prediction uncertainty via the law of total variance. For a Bayesian neural network with random parameters :
often referred to as “aleatoric” (within-model) vs. “epistemic” (between-model) uncertainty.
Actuarial Science
Credibility theory uses the same partitioning: the expected value of process variance (EVPV), and the variance of hypothetical means (VHM), The ratio of explained to total variance determines how much “credibility” to give to individual risk classifications.
Information Theory
For jointly Gaussian , the fraction relates directly to the mutual information In non-Gaussian settings, a high explained-variance ratio still indicates significant information about Y contained in X.
Generalizations
The law of total variance generalizes to multiple or nested conditionings. For example, with two conditioning variables and :
More generally, the law of total cumulance extends this approach to higher moments.
See also
- Law of total expectation (Adam’s law)
- Law of total covariance
- Law of total cumulance
- Analysis of variance
- Conditional expectation
- R-squared
- Fraction of variance unexplained
- Variance decomposition
References
- Blitzstein, Joe. "Stat 110 Final Review (Eve's Law)" (PDF). stat110.net. Harvard University, Department of Statistics. Retrieved 9 July 2014.
- "Law of total variance". The Book of Statistical Proofs.
- Billingsley, Patrick (1995). "Problem 34.10(b)". Probability and Measure. New York, NY: John Wiley & Sons, Inc. ISBN 0-471-00710-2.
- Weiss, Neil A. (2005). A Course in Probability. Addison–Wesley. pp. 380–386. ISBN 0-201-77471-2.
- Bowsher, C.G.; Swain, P.S. (2012). "Identifying sources of variation and the flow of information in biochemical networks". PNAS. 109 (20): E1320 – E1328. doi:10.1073/pnas.1118365109.